
How MetaDB works
How does METADB work?
MetaDB is a software for statistical analysis and census of online websites. MetaDB is based on a standalone web crawler, called METADBot,which analyzes only the homepages of online websites, starting from a very narrow subset of sites (about 750,000 websites), and moving from site to site taking advantage of outbound links with a technique known as Snowball Sampling.
MetaDB analyzes only the homepages of scanned websites.
Why so little information? To collect the statistical analysis and census information that MetaDB is interested in, just one page of the site, precisely the homepage.
This is because MetaDB wants to analyze only the following factors:
- High-level kinship relationships between websites (interlinking)
- Web server in use and its hosting provider
- HTML usage patterns
- Types of technologies used on the site, and their metadata (e.g. Wordpress template type)
MetaDB starts from a narrow set of initialwebsites, which "kicks off" the analysis operations. The initial scanned group of websites is a list of about 1,250,000 of the most visited websites in the world.
Then, by analyzing the HTML of each site, MetaDB is able to verify which other websites are linked directly with a <a> tag,either through a script, or through a >link tag. Its link is "purified", that is, the only part related to the domain nameis retained, and the domain name is placed in the queue of sites to be scanned, if it is not already in the queue.
This operation is called Snowball Sampling and allows you to create a kind of "map of the stars" of all websites, giving the crawler enough time to scan for all the sites in the queue.
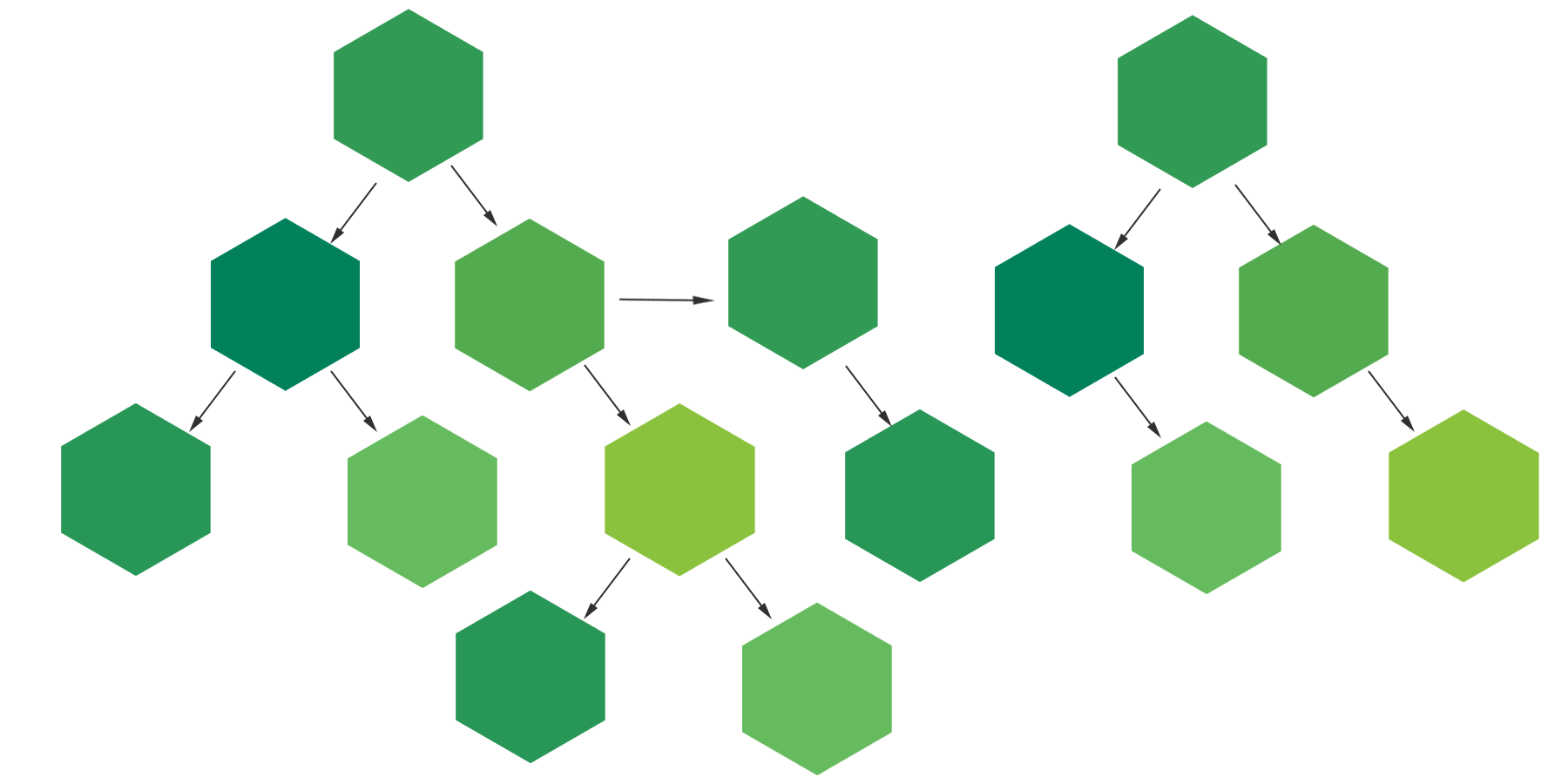 How a web crawler works
How a web crawler works
Why does MetaDB have so few sites analyzed compared to the total of the world's websites?
Some sources cite the fact that there are about 400 million active and functioning websites, and to analyze all these sites, MetaDB would need:
- A lot of computing power
- Several HTML code gathering workers intelligently located across continents
- Access to official and updated databases of registered domain names, for each TLD
- A lot of storage capacity, in the order of tens of Terabytes
The Snowball Sampling technique alone is not enough. Over time, in several successive attempts to make MetaDB work properly, we realized that we always got to a point beyond which it was impossible to determine new domain names that could be queued for analysis. This is why this technique is only suitable for making a statistical analysis of nonprobability sampling,which only give an idea of what would happen if the set (the "sample") were larger. In any case, we would like to point out that the data collected by MetaDB is subject to a structural bias,as the domain names queued for analysis are always somehow linked to the parent nodes. This can lead to aggregated statistics moving away, in a way that is not yet known, from a normally Gaussian distribution.
What does METADBot do on my site?
When METADBot scans your website's Homepage ( always and onlythe Homepage!), it takes notes on outgoing links, the HTML code used, the Hosting server used, and the technologies used by your site, and adds them to our database. Periodically scans your website again to check the current status of the previously found data. Our crawler does not collect or store any other information on your website.
METADBot Does not slow down your website in any way and does not activate advertisements (if any) and does not affect the inbound traffic of your site, not affecting the data of your analytics tools such as Google Analytics. Remember, METADBot scans your site's Homepage alone. A few dozen kilobytes, nothing more.
Does METADBot comply with the directives on Robots files.txt?
Absolutely yes!
Before scanning your site's Homepage HTML, METADBot downloads the robots file.txt (if any) to your server, and, if disabled, goes no further.
METADBot always identifies with the user agent Mozilla/5.0 (compatible; METADBot/1.6; +https://metadb.co/en/how-it-works)

METADBot
- Version: 1.6
- Bot type: Good (identify himself, always!)
- Obeys robots.txt file
- User-agent: Mozilla/5.0 (compatible; METADBot/1.6; +https://metadb.co/en/how-it-works)
What technologies does MetaDB use in order to work?
MetaDB's architecture consists of multiple services that bring this website to life.
- METADBot, the bot that physically downloads the HTML source codes of the target domains
- MetaDB Core Analyzer, the heart of the MetaDB project, which performs aggregated statistical analysis and saves data within the Mysql database to support analysis operations
- MetaDB Api, a simple Api system to support public https://metadb.co
- https://metadb.co, this website
What technologies does MetaDB use to work? MetaDB Core Analyzer was written entirely in PHP and Perl. The database used for analysis is MariaDB 10.3. MetaDB Api was also written in PHP, as well as this website, which uses PHP/CSS/jQuery
How much source code was written for MetaDB? All of the services listed above to support everything that makes MetaDB work, collectively count more than 45000 lines of source code , for about 2MB of code, with an average code length per line of 78 characters.